
Multimodal foundation models, such as GPT-4o, have made remarkable progress recently. However, it is not clear how well these models understand vision in detail, especially when it comes to tasks beyond question answering. In this paper, we benchmark the performance of popular multimodal foundation models (GPT-4o, o4-mini, Gemini 1.5 Pro and Gemini 2.0 Flash, Claude 3.5 Sonnet, Qwen2-VL, Llama 3.2) on standard computer vision tasks (semantic segmentation, object detection, image classification, depth and surface normal prediction) using established datasets (e.g., COCO, ImageNet and its variants, etc). The main challenges in performing this analysis are:
Prompt chaining is a technique designed to help MFMs break down complex tasks into simpler, manageable sub-tasks. We develop prompt chains for all of the tasks we evaluate, namely, object detection, semantic segmentation, grouping, depth prediction, and surface normal prediction. To guide the choice of how to split each task into sub-tasks, we rely on our early key observation that most MFMs are relatively strong at image classification, and therefore try to split each task into multiple classification sub-tasks.
We divide the task into two stages. First, the model identifies all objects in the image. Then, it localizes each object by recursively zooming in. We divide the image into grid cells and ask the model to check if any part of the object is in each cell. The model discards empty cells, narrowing the search area. By using both coarse and fine grids, we quickly downsample and refine the object's edges, pinpointing its location.
In semantic segmentation, the goal is to assign a class label to each pixel in an image. Instead of querying each pixel individually, we group pixels using SLIC, removing the need for per-pixel queries. Superpixels segment the image into smaller, homogeneous regions based on features like color and texture. We then classify these superpixels in batches, leveraging the strength of MFMs in image classification. To improve accuracy, we include previous batch predictions in the chain and provide multi-scale crops of each superpixel, which enhances the model's ability to capture fine details.
In the grouping task, given an image and a query point, the goal is to find other pixels that belong to the same object or background. Unlike semantic segmentation, this task has no fixed set of classes, making it more challenging. We use superpixels and leverage the MFM's ability to assess visual similarity. Each superpixel acts as a node in a graph, with edges connecting neighboring superpixels. Starting from the query point, the model evaluates adjacent superpixels to determine if they belong to the same object. This process continues, merging relevant superpixels, until no more are added.
Predicting 3D depth from a single 2D image is inherently ambiguous, so we perform relative depth prediction by having the model rank different regions of the image based on their distance from the camera. Instead of querying individual pixels, we segment the image into superpixels and sample pairs of superpixels for comparison. The model ranks these pairs by relative depth. These pairwise rankings are then globalized using an objective function that assigns larger values to deeper superpixels. We assume all pixels within a superpixel share the same depth, allowing us to extend superpixel-level rankings to a pixel-wise depth map across the image.
For surface normal prediction, we use a similar ranking approach as with depth. We select standard basis vectors (right, up, and forward) as reference directions and query the model to compare randomly sampled superpixel pairs based on their alignment with each vector. The pairwise comparisons are then globalized using the same algorithm as for depth, resulting in three separate surface normal maps. As before, we assume uniformity within each superpixel, assigning the same rank to all pixels within a superpixel group.
Here, we showcase the ability of MFMs to perform multiple tasks on the same image, using prompt chaining. The visuals are generated using GPT-4o, and demonstrate a strong semantic understanding of the images, and a non-trivial but relatively weaker understanding of geometric properties.


Hint: Drag the slider to change the task. Use the buttons to explore different images.
Here, we provide a visual comparison between the predicted outputs of various models and the ground truth across all tasks.
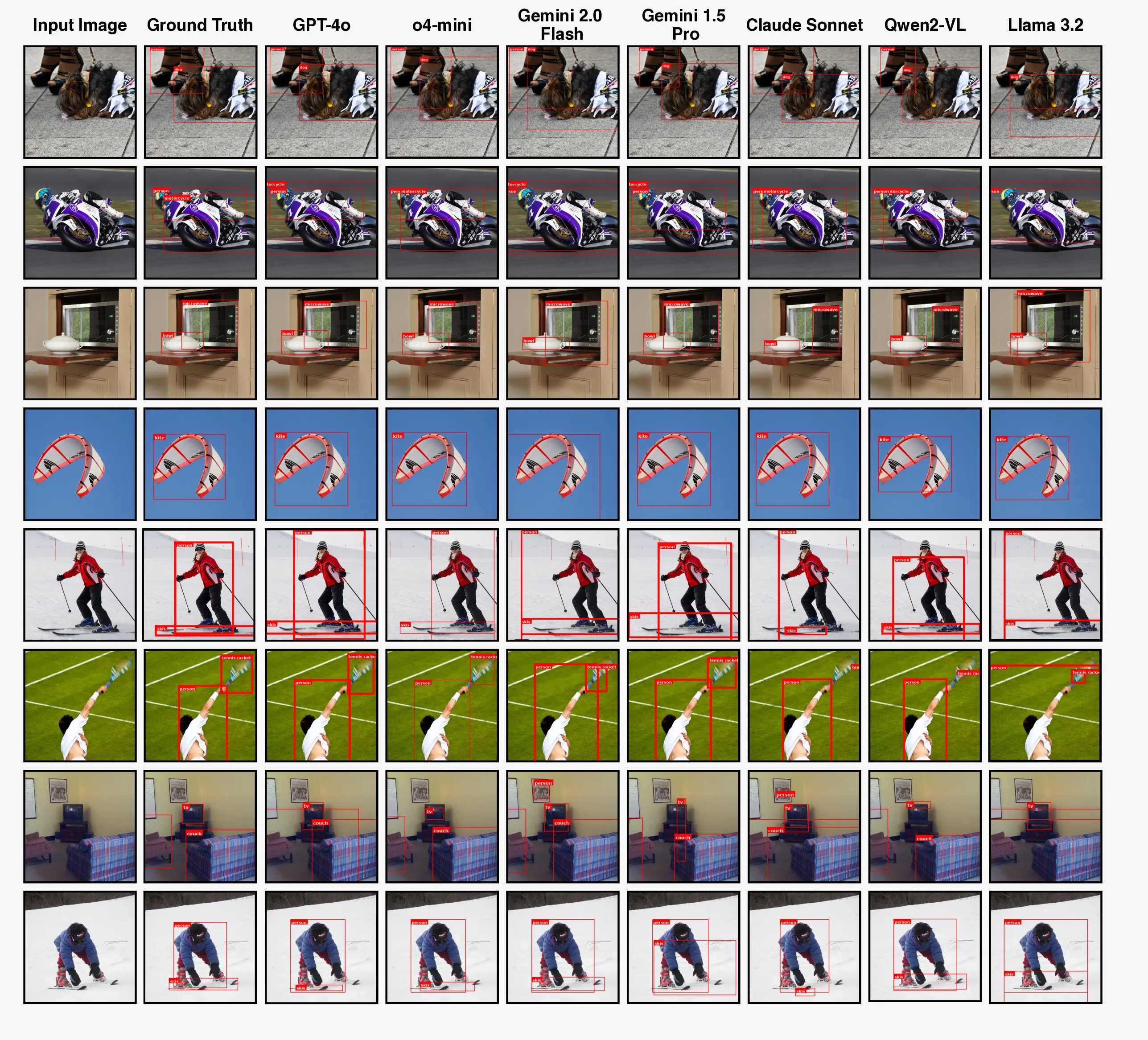
Hint: Use the buttons to explore different images.
Hover over the original image to see different overlayed segmentations based on your cursor's position. The masks were generated using GPT-4o. The gray points indicate the query points used to generate the segmentations.

Hint: Move your cursor over the image to explore different segmentations. Use the buttons to explore different images.
An RGB input is shown on the left and the model's predictions on the right, obtained for each frame of a video. Users can use the slider to navigate through frames, observing how the model changes its predictions over time.


Hint: Drag the slider to change the frame. Use the buttons to explore different tasks.
We evaluated reasoning models, including o1 and o3, on a smaller subset of our data, using GPT-4o as a baseline. The results, summarized in the spider chart, show that while these models perform comparably to GPT-4o on semantic tasks, they exhibit a stronger performance on geometric tasks.
We also experimented with varying the reasoning effort for o4-mini. While we observed some improvement with medium and high reasoning effort compared to low, the trend was not consistent across all tasks. For a deeper dive into these experiments, please see the paper and the supplementary.

Recent updates to GPT-4o allow it to generate dense image outputs instead of just text, which is a promising development for vision tasks. However, these new image generation features exhibit several limitations. Specifically, we observe that generated outputs suffer from spatial misalignments and hallucinations. This presents challenges in directly applying this model to vision tasks, which we leave to future work to address. The figure below highlights some of these failure cases.

Failure cases of GPT-4o with image generation capability. Despite the model's promising capabilities, limitations remain. Here, we highlight some typical failure modes: hallucinations (marked in dotted blue) and inaccurate predictions (marked in dotted green).
Here, we quantitatively explore how different MFMs perform across various visual tasks. As described earlier, we tested GPT-4o, o4-mini, Gemini 1.5 Pro and 2.0 Flash, Claude 3.5 Sonnet, and Qwen2-VL-72B, comparing their capabilities to specialized vision models.
Our classification testing revealed interesting results across all datasets. While MFMs didn't quite match the performance of specialized vision models like Model Soups ViT-G and OpenCLIP H, they showed impressive capabilities. GPT-4o emerged as the standout performer, followed by Gemini 2.0 Flash, Gemini 1.5 Pro, Claude 3.5 Sonnet, Qwen2-VL, o4-mini and Llama 3.2. Notably, these models demonstrated good resilience to image corruptions and distribution shifts.
| Corruptions | Domain Shift | |||||
|---|---|---|---|---|---|---|
| Model | ImageNet | ImageNet-V2 | 2DCC | 3DCC | ImageNet-R | ImageNet Sketch |
| Model Soups ViT-G | 90.94 | 84.22 | - | - | 95.46 | 74.23 |
| OpenCLIP H | 84.37 | 78.33 | 66.96 | 65.95 | 93.76 | 73.24 |
| GPT-4o | 77.20 | 71.57 | 62.46 | 61.13 | 84.38 | 67.30 |
| o4-mini | 55.90 | 46.99 | 37.22 | 36.68 | 56.05 | 45.18 |
| Gemini 2.0 Flash | 74.78 | 75.79 | 55.67 | 56.92 | 82.05 | 69.43 |
| Gemini 1.5 Pro | 73.88 | 69.76 | 56.14 | 56.22 | 71.42 | 57.15 |
| Claude 3.5 Sonnet | 62.85 | 54.45 | 40.76 | 41.41 | 70.36 | 57.42 |
| Qwen2-VL | 55.54 | 49.39 | 38.92 | 36.45 | 66.31 | 51.18 |
| Llama 3.2 | 49.15 | 48.21 | 34.45 | 34.37 | 65.05 | 47.11 |
In object detection tests on a subset of the COCO dataset, we compared the MFMs against specialized vision models like DETR and Co-DETR. While all MFMs performed below these specialized models, GPT-4o achieved the highest performance among the MFMs, significantly outperforming others. Interestingly, even when testing Gemini 1.5 Pro and Qwen2-VL with direct bounding box regression, they still couldn't match GPT-4o's performance with the chain algorithm.
| Baselines | Model | AP50 | AP75 | AP |
|---|---|---|---|---|
| Vision Specialists | Co-DETR | 91.30 | 86.17 | 80.23 |
| Co-DETR + Chain | 90.06 | 52.78 | 51.54 | |
| DETR | 73.31 | 63.61 | 58.67 | |
| DETR + Chain | 72.33 | 38.36 | 39.36 | |
| 4M-21 | 59.54 | 51.57 | 47.71 | |
| 4M-21 + Chain | 55.46 | 30.48 | 30.74 | |
| MFMs | GPT-4o | 60.62 | 31.97 | 31.87 |
| o4-mini | 42.90 | 22.18 | 22.60 | |
| Gemini 2.0 Flash | 44.17 | 15.83 | 19.85 | |
| Gemini 1.5 Pro | 39.75 | 15.27 | 18.11 | |
| Claude 3.5 Sonnet | 31.69 | 12.13 | 14.78 | |
| Qwen2-VL | 35.62 | 12.82 | 15.27 | |
| Llama 3.2 | 31.87 | 8.40 | 12.83 | |
| Control | Oracle + Chain (pred. class) | 75.44 | 41.31 | 41.56 |
| Oracle + Chain (full) | 92.18 | 49.33 | 50.14 | |
| Blind guess | <0.01 | <0.01 | <0.01 |
For semantic segmentation on a subset of COCO, the MFMs achieved notable but not state-of-the-art performance. While they showed promising capabilities, they still fell behind specialized models like OneFormer.
In our grouping task evaluation, which built upon semantic segmentation, we saw varying levels of success among the MFMs. GPT-4o emerged as the top performer, showing good overall performance, though still not matching the capabilities of the specialized SAM model.
| Baselines | Model | mIoU | Pixel Accuracy |
|---|---|---|---|
| Vision Specialists | OneFormer | 65.52 | 83.26 |
| OneFormer + Chain | 60.64 | 81.69 | |
| 4M-21 | 54.31 | 79.66 | |
| 4M-21 + Chain | 52.72 | 78.59 | |
| MFMs | GPT-4o | 44.89 | 68.60 |
| o4-mini | 39.19 | 64.26 | |
| Gemini 2.0 Flash | 43.04 | 66.15 | |
| Gemini 1.5 Pro | 40.46 | 64.88 | |
| Claude 3.5 Sonnet | 32.05 | 58.41 | |
| Qwen2-VL | 33.59 | 56.36 | |
| Llama 3.2 | 36.63 | 59.95 | |
| Baselines | Oracle + Chain | 83.41 | 94.68 |
| Blind guess | 0.03 | 0.29 |
| Models | mIoU |
|---|---|
| SAM | 80.12 |
| SAM + Chain | 72.32 |
| GPT-4o | 59.06 |
| o4-mini | 46.00 |
| Gemini 2.0 Flash | 55.25 |
| Gemini 1.5 Pro | 44.13 |
| Claude 3.5 Sonnet | 41.68 |
| Qwen2-VL | 21.64 |
| Llama 3.2 | 25.69 |
| Oracle + Chain | 81.77 |
Our depth prediction task on a subset of Hypersim images revealed that while MFMs performed better than random guessing, they still showed significant limitations compared to specialized models like Omnidata. Quantitatively, their geometric abilities appear relatively weaker than their semantic abilities. We evaluated performance using both standard metrics and relative measurements like Spearman correlation coefficients and pairwise depth comparison accuracy.
| Baselines | Method | Higher is better ↑ | Lower is better ↓ | ||||
|---|---|---|---|---|---|---|---|
| δ₁ | δ₂ | δ₃ | ρ | Accuracy | AbsRel | ||
| Vision Specialists | Omnidata | 0.768 | 0.867 | 0.911 | 0.95 | - | 0.375 |
| Omnidata + Chain | 0.568 | 0.772 | 0.864 | 0.81 | 93.74 | 0.528 | |
| 4M-21 | 0.636 | 0.814 | 0.888 | 0.89 | - | 0.406 | |
| 4M-21 + Chain | 0.565 | 0.774 | 0.865 | 0.81 | 88.25 | 0.529 | |
| MFMs | GPT-4o | 0.459 | 0.712 | 0.838 | 0.53 | 70.59 | 0.621 |
| o4-mini | 0.467 | 0.718 | 0.841 | 0.58 | 74.08 | 0.595 | |
| Gemini 2.0 Flash | 0.461 | 0.715 | 0.839 | 0.59 | 71.11 | 0.615 | |
| Gemini 1.5 Pro | 0.458 | 0.709 | 0.835 | 0.51 | 66.78 | 0.628 | |
| Claude 3.5 Sonnet | 0.429 | 0.693 | 0.830 | 0.48 | 68.09 | 0.657 | |
| Qwen2-VL | 0.432 | 0.698 | 0.831 | 0.41 | 64.44 | 0.637 | |
| Llama 3.2 | 0.458 | 0.711 | 0.835 | 0.53 | 67.51 | 0.608 | |
| Control | Oracle + Chain | 0.571 | 0.774 | 0.863 | 0.83 | 100.0 | 0.528 |
| Blind Guess | 0.375 | 0.628 | 0.773 | 0.25 | 54.24 | 0.758 | |
The surface normal prediction task revealed some significant limitations in the MFMs' 3D understanding capabilities. Most notably, several models struggled with left-right direction correlation, with some showing negative correlation for certain directions, revealing a systematic bias in their understanding of these directions. These results suggest that MFMs currently have limited 3D visual understanding capabilities.
| Baselines | Method | ρx | ρy | ρz |
|---|---|---|---|---|
| Vision Specialists | Omnidata | 0.78 | 0.83 | 0.80 |
| Omnidata + Chain | 0.64 | 0.70 | 0.58 | |
| 4M-21 | 0.71 | 0.74 | 0.65 | |
| 4M-21 + Chain | 0.65 | 0.70 | 0.56 | |
| MFMs | GPT-4o | -0.14 | 0.57 | 0.40 |
| o4-mini | 0.22 | 0.61 | 0.46 | |
| Gemini 2.0 Flash | -0.39 | -0.04 | 0.02 | |
| Gemini 1.5 Pro | -0.17 | -0.57 | 0.04 | |
| Claude 3.5 Sonnet | -0.19 | 0.61 | 0.40 | |
| Qwen2-VL | 0.09 | -0.07 | 0.02 | |
| Llama 3.2 | 0.41 | -0.42 | 0.22 | |
| Control | Oracle + Chain | 0.64 | 0.70 | 0.60 |
| Blind guess | -0.48 | -0.61 | 0.11 |
We defer a detailed discussion of several design choices and experimental results to the main paper. Topics covered include:
@misc{ramachandran2025doesgpt4ounderstandvision,
title={How Well Does GPT-4o Understand Vision? Evaluating Multimodal Foundation Models on Standard Computer Vision Tasks},
author={Rahul Ramachandran and Ali Garjani and Roman Bachmann and Andrei Atanov and Oğuzhan Fatih Kar and Amir Zamir},
year={2025},
eprint={2507.01955},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.01955},
}